One of the common challenges of on-demand large datasets processing is the time required for data processing. The naive approach computes operation results on the same component as serves results (and horizontally scale the system when overloaded). The more complex (and generally speaking the only correct) approach is to use some asynchronous task queue based on distributed message passing (message broker). Another option is to stream data continuously as they come.
The rationale behind this article
Developing web applications that process big data sets (like satellite images or videos) has specifics. It is good to be aware of them, especially when you come from a different field of software engineering, like the development of desktop applications or web applications based strictly on a relatively fast relational database. Often, when developers come from projects that mainly operate with small amounts of data (typically some information systems), they tend to use the most straightforward approach. It means processing all data and returning the result in one call (by accessing some GET route in your system). That is in many cases acceptable - if you access some fast database (or even file) that is perfectly optimized - you do not risk any timeouts (or some bad user experience). But, generally speaking, this approach is absolutely not acceptable for the processing of big data sets.
It is not rare to see a good developer who does not know how to deal with this issue (or do not even realize there is any). Often, even a time is a factor - creating one route that synchronously processes everything is much simpler than the whole asynchronous event-driven system. So, even though your work is conceptually wrong, you accept this technical debt and deploy it. However, using this approach can quickly destroy your business. That is typical for many start-ups that often do not attract elite developers, create something that works for one user, but when they go to market, everything fails (as the number of users increases).
It is beneficial to know how to proceed correctly, and what (ready-made) technologies exist to avoid this bitter scenario. Knowing how weird it might sound, it is crucial to start your project (even if it is just a proof of concept) using the correct approach, as it ultimately saves a lot of time and resources. If you are a beginner in the field, it might be helpful to carefully study available open-source projects before designing and implementing your solution. Reading about technologies like GeoServer, Celery, RabbitMQ, Apache Kafka, Faust, WebSocket, and others might help you.
Why not use the naive (synchronous) approach and what it is?
The picture below schematically represents the naive approach logic. As you can see, the crucial part of the naive approach is the load balancer that distributes the tasks to workers and returns in the same relation return the results to users. All is happening in one call - the response contains the required data.
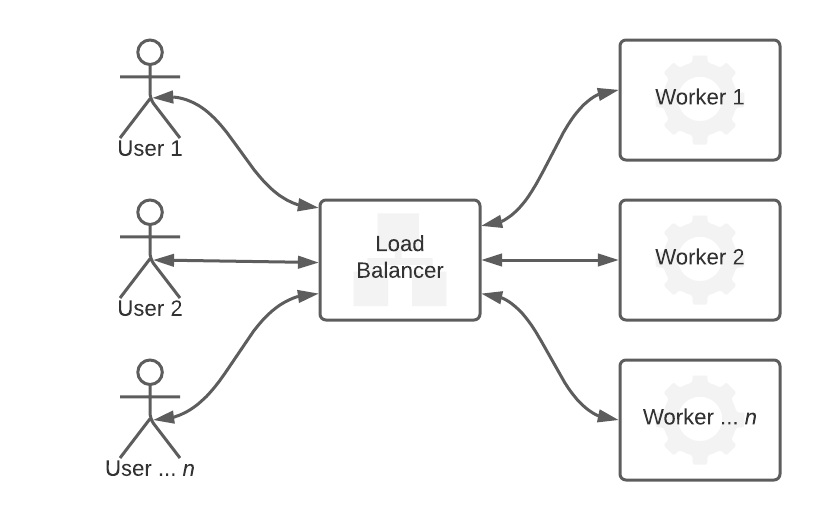
The bottleneck of this approach is that the task complexity determines the response time. For example, you have to wait until the computation finishes when processing extensive data sets (like creating a map or finding the average value of something large). This causes significant troubles related to the connection timeouts (mainly loss of the connection before computation finishes) and increases the complexity of the logic running on a user side (as there is a need to expect that timeout happens). Also, no other user can send a request to the server during the computation, which reduces the system throughput (as well as the number of users that can connect simultaneously). To keep such a system alive is extremely expensive as the number of workers has to increase linearly to the number of users.
The naive approach is, generally speaking, an incorrect approach (and flawed logic) for any application in production.
What is the correct approach? To use task queues and message passing (so-called event-driven architecture)
The picture billows demonstrate the simplified logic of the task queue approach (however, it includes all essential components).
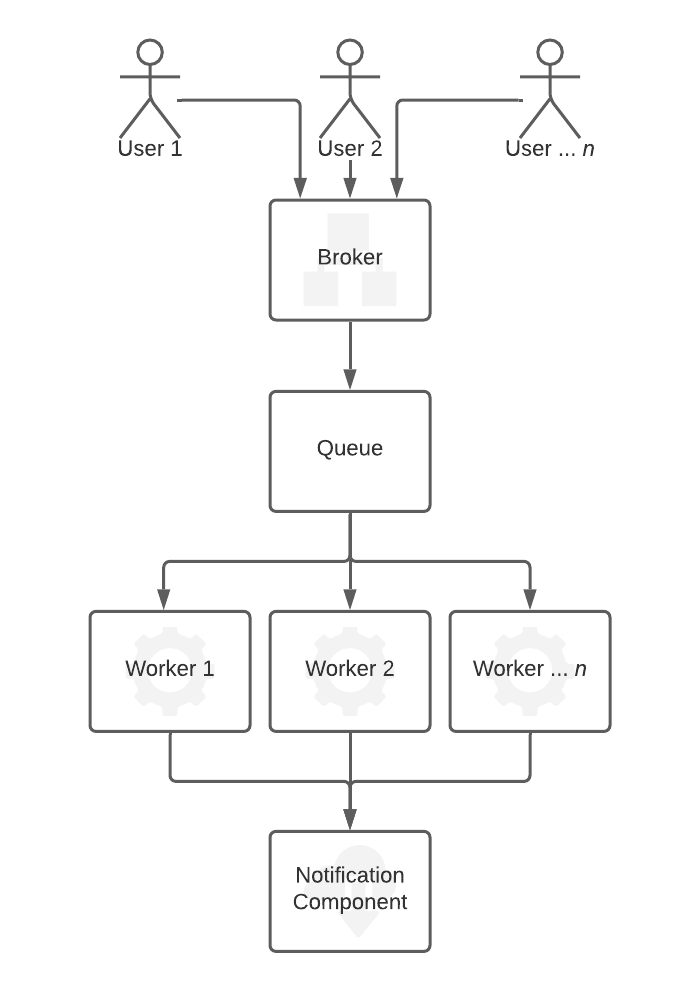
The logic is that there is just one (or a small number) light-weighted "front" worker called broker (typically a back-end service). The broker does not do any complex computations. Instead, if a user wants to compute anything, the broker creates a message (command/instruction) defining the task and passes it to the task queue. The task queue is just a queue of these instructions asynchronously distributed to the workers. Typically immediately after the worker finishes the previous job, it fetches the new task from the queue.
After the worker completes the computation, the result is usually stored in a database (usually a fast in-memory database), and the user is notified. Notification is typically sent separately by another entity - it can be a WebSocket interface, an email server, or any implementation-specific solution. Then, when the user wants to see the results (after receiving the notification), it just asks the front worker to fetch them. That is a simple task performable synchronously as it does not require any computation time. The usual way to identify tasks is to use some unique ID (like a UUID identifier).
Pros of the task queue approach
The main advantage of the presented approach is that the broker is just a simple application (web service). It has a significant impact on the system's throughput, overall complexity, security, and the price of components. Also, any user can connect whenever wanted and always receives a response with minimal latency. Another advantage is that tasks from the queue are passed asynchronously to workers, making tasks distributed optimally. The approach also allows optimizing the system based on the number of tasks in the queue - it can spin-off more workers when the system is busy and vice versa (this is particularly helpful in a cloud-based environment).
Available technologies
Available technologies depend on the solution that you choose. In the Python land, the simple approach is to use Celery based workers and RabbitMQ (or Redis) based task queues. Both are under open licences and use free and widely supported technologies for storing/accessing data (Redis / Memcached). Another option is to use Faust (as a broker and worker interface) + Apache Kafka (as task queue) combination. The advantage of Celery is that code for workers is written as it were a code of the main application (broker), making the codebase easier to maintain. The disadvantage of Celery is that it is hard to follow the task state based on its ID as Celery cannot separate inexisting (e.g. lost) tasks from tasks that any worker has not accepted (therefore are in the queue).
Is there something in the middle? Yes, the streaming logic based on WebSocket
There is also a way based on a combination of previous approaches. Technically, it is helpful when your application processes data sets where results are splittable into small chunks. For example, in the case of splitting the video into frames - you do not need to wait till the whole video is processed to work with already generated frames.
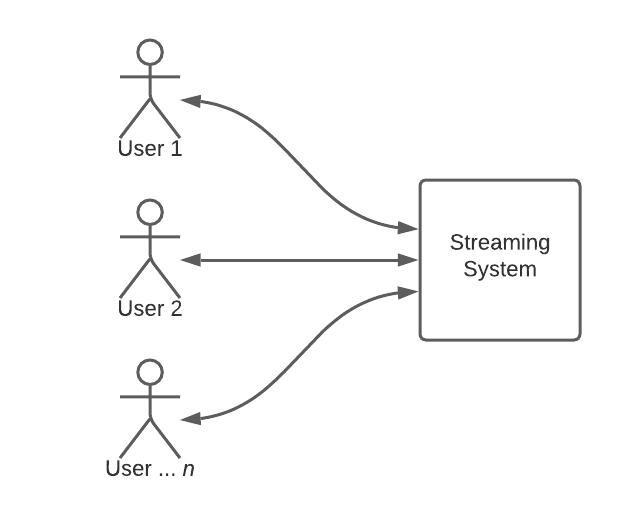
The logic is based on the asynchronous connection between client and server - that is performable using WebSocket. So, technically, instead of sending a notification about finishing the task, the server sends results continuously as they come. That makes the network connection optimally busy all the time, and there is no risk of timeout (because of WebSocket).
Although streaming logic seems to be an optimal approach (if it is deployable) - the reality is not that optimistic. There are many technical challenges when it comes to implementation. For example, keeping a WebSocket connection open is resource hungry operation (both CPU time and memory to keep the connection alive are required). Currently, there is no available correctly working open-source framework to manage WebSocket streaming for larger systems (with many customers).
Summary
This article presents three ways of dealing with big-data processing for web applications. One uses the naive (synchronous) approach with one heavy-weighted worker, and another uses a message broker (task queue) approach or continuous streaming using WebSocket. The naive approach is unsuitable for practical problems (can only prove that concept works). The task queues approach is initially more difficult for implementation but is more flexible, and the system's throughput is more significant (as well as the system's security). Even the price for deploying such a system is lower. The third option is to stream data continuously. If this option is possible, it is the optimal one. Unfortunately, no simple, ready-made open-source implementation is currently available.
❋ Tags: Task Queue Big Data Python Design Performance