There are many common challenges in systems that process large data sets like videos, images, large feeds and similar. One of the most important decisions is whether to deploy infrastructure on some cloud service or if it is better to use an on-premises solution. Ultimately, if you decide to use a cloud-based solution, other challenges arise, like which provider would be the best one, how to deploy - use infrastructure as a code, or just some simple solution etc. Also, there are many interesting services that are cheap or free and can be helpful like Dropbox.
What systems do we analyse?
This article mainly focuses on systems that operate with larger files like images, videos, feeds (and similar massive data sets). The common feature of these systems is that just a single data file can have many gigabytes, and the system needs many datasets to operate. A typical example might be a system for predicting the energy of renewable resources (like solar photovoltaic panels, wind turbines or wave devices) that uses satellite images. Another example can be a system that process videos and classify frames. Unfortunately, both satellite images and videos are notoriously massive files, and it is often impossible to load them into operational memory.
Requirements for infrastructure
The key requirements are that data must be quickly available, stored as cheaply as possible, and the reading and writing speed must be good. As you can guess, it is technically not viable to have all these features simultaneously. In the best case, just two out of these three options, sometimes even less. The cloud-based solution can offer you a distributed infrastructure with low latencies - but it is certainly not cheap. On the other hand, it is often cheaper and quicker if you have an on-premises solution but availability (access latency) is much lower (for example when accessing from abroad).
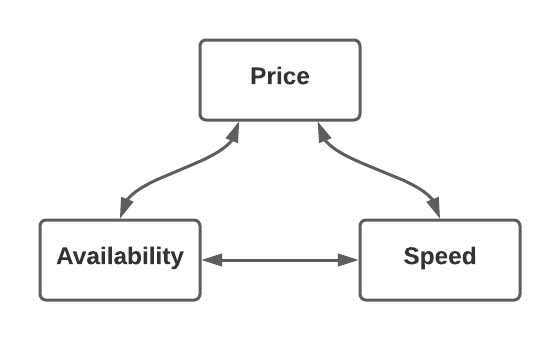
You can find many other similar dilemmas when selecting the correct infrastructure or any technology in general. The characteristic feature of these triangular choices is that only up to two options are available at one time (sometimes not even that).
Local, production and other stacks
A very important concept in full-stack engineering is called a stack. Essentially it is a virtual working space where the development (or deployment) is performed. There are usually at least two stacks - local (aka development) and production one. A development stack is usually created using docker-compose and you can run it locally on your development machine. It should be as much similar to the production stack as possible (using the same technologies, techniques etc.). Many commercial technologies, such as S3 (storage buckets), Elasticsearch, etc. have docker images ready to be used in the local stack (for AWS it is called "localstack"). A production stack is usually defined in Terraform (or Kubernetes). It actually represents the application as it runs on the cloud (or anywhere else). There are often other stacks - such as staging and testing - which are helpful when deploying bigger applications (or whenever bugs matter).
Dockerizing of components
As mentioned above, stacks (production, local, staging) use docker images (or related technologies). Docker image is essentially a lightweight virtual machine that is coded in a special file. The way how to code an entity differs from case to case - often the sufficient way is to use a ready-made image from Docker hub. The customization of such a container is usually done using environmental variables. This is a typical approach for things like databases (PostgreSQL, REDIS). There are also many commercial images outside of the Docker hub - like things for better simulation of AWS services. When it comes to custom created docker images, it is a usually trivial task to dockerize things. However, in many cases (like in the case of older software) it can be quite a challenging task. Usually, the services that are the least important consumes the most DevOps time (famously service called GeoServer).
Cloud-based solutions
There are many cloud-service providers - the most popular ones are Google Cloud Platform, Amazon Web Services, and Microsoft Azure. Many other smaller providers also exist. If it comes to main providers - it is quite difficult to find many differences - provided services are similar in both quality and pricing. Naturally, some of them are better for one or another technology - Azure for Windows-based services, AWS for DynamoDB or S3, G-Cloud for everything from Google, etc. When it comes to prices, for a typical application that deals with large datasets, it is usually something around £1000 - £3000 per month (in 2021 price level).
Small providers usually offer either dedicated servers or virtual machines where you need to deploy your own logic using Kubertness, Docker Swarm or similar technology. Prices are usually cheaper - but you need to consider one important aspect - components in infrastructure are always on and running - at least, usually. Big cloud infrastructure providers bill every minute when any resource is on - so you can set up a smart policy that just spins on a particular resource just for the time when is really needed and then turns it off again (this can save a lot of money).
Generally, setting infrastructure correctly is not always a simple task. The usual approach is to use Infrastructure As A Code (IAAC), like Terraform that can help to set up services and policies - like when to run a particular instance, security, access management, etc. For many popular applications (e. g. CKAN, WordPress), they are usually some ready-made solutions on GitHub. Some popular things (e. g. Elasticsearch, databases) have instances ready as a service (on most cloud-service providers), which might save a lot of time with configuration.
On-premises solution
A special case is a solution when all servers (machines) are literally physically present in the office - called an on-premises solution. Although this approach is considered by many people as an anachronism, it is still applicable and meaningful for many applications. There are also cases when this is the only way - for example when processing sensitive datasets (like secret data, or medical records).
The main disadvantage is that hardware requires maintenance (often a special employee), computers require physical space, and there are many additional costs (particularly for electricity bills). Advantages are also quite clear - you can rely on your own infrastructure, use it whenever want, etc. In many cases, on-premises computers provide the cheapest way - for example when used for scientific computations or similar time-consuming processes (e. g. video processing, satellite image classification). It is because cloud-based services are really expensive when powerful machines are required.
Useful SAAS
There are many useful SAAS (software as a service) tools that can be used for development. For example, a free account on Dropbox (or Google Drive) can work as archive storage for larger files. The same holds true for similar services around Office 365. In many cases (like in the case of Dropbox), there is also API for most of the programming languages that allows handling stored files. In many cases, there is also no need to pay for expensive SAAS on cloud-like in the case of SMTP servers - as it can easily run externally (and use cheap web hosting). Similarly, OpenStreetMap can work sufficiently for most cases and does not require any expensive license. It is often good to take your head out of the box and think about things from a wider perspective (especially if there is no near-unlimited budget available).
Summary
There are many things that have to be considered when the infrastructure for the application is planned. One of the most common challenges is whether the system should run on the cloud or rather on-premisses. Cloud services provide many comfortable ready-made solutions but are generally speaking quite expensive. One of the biggest advantages of cloud services is the possibility to run your solution just in time (so no computer has to run permanently). The on-premises solution is in many cases cheaper (especially when used for some longer computations). Also, there are many less known services outside of cloud-service providers that can save a lot of money (like using Dropbox for archiving).
❋ Tags: Python Design DevOps Big Data Web application